https://canro91.github.io/2020/09/28/SQLServerTuningTips/
Six SQL Server performance tuning tips from Pinal Dave
28 Sep 2020 #sqlRecently, I’ve needed to optimize some SQL Server queries. I decided to look out there what to do to tune SQL Server and SQL queries. This is what I found.
At the database level, turn on automatic update of statistics, increase the file size autogrowth and update the compatibility level. At the table level, delete your unused indexes and create the missing ones, keeping around 5 indexes per table. And, at the query level, find and fix implicit conversions.
While looking up what I could do to tune my queries, I found Pinal Dave from SQLAuthority. Chances are you have already found one of his blog posts when searching for SQL Server tuning tips. He’s been blogging about the subject for years.
These are six tips from Pinal’s blog and online presentations I’ve applied recently. Please, test these changes in a development or staging environment before making anything on your production servers.
1. Enable automatic update of statistics
Turn on automatic update of statistics. You should turn it off if you’re updating a really long table during your work-hours.
This is how to enable automatic update of statistic update. [Source]
USE <YourDatabase>;
GO
-- Enable Auto Create of Statistics
ALTER DATABASE <YourDatabase>
SET AUTO_CREATE_STATISTICS ON WITH NO_WAIT;
-- Enable Auto Update of Statistics
ALTER DATABASE <YourDatabase>
SET AUTO_UPDATE_STATISTICS ON WITH NO_WAIT;
GO
-- Update Statistics for whole database
EXEC sp_updatestats
GO
2. Fix File Autogrowth
Add size and file growth to your database. Make it your weekly file growth. Otherwise, change it to 200 or 250MB.
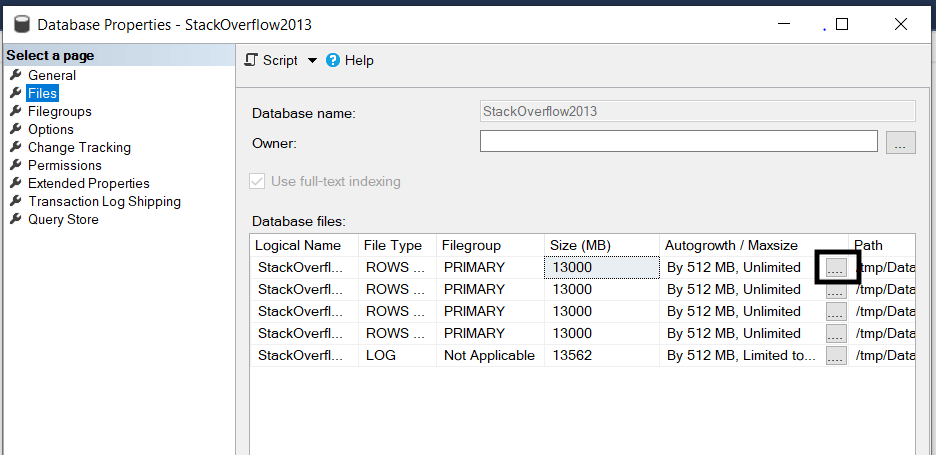
From SQL Server Management Studio, to change the file autogrowth, go to your database properties and then to Files. Click on the three dots in the Autogrowth column. And, change the file growth.
3. Find and Fix Implicit conversions
Implicit conversions happen when SQL Server needs to convert between two data types in a WHERE or in JOIN.
For example, the query below with OrderNumber as a VARCHAR(20) has implicit warning when we compare it to a INT parameter.
DECLARE @OrderNumber INT = 123;
SELECT *
FROM dbo.Orders
WHERE OrderNumber = @OrderNumber;
GO
To run this query, SQL Server has to go through all the rows in the dbo.Orders table to convert the OrderNumber from VARCHAR(20) to INT.
To decide when implicit conversion happens, you can check Microsoft Data Type Precedence table. Types with lower precedence convert to types with higher precedence. For example, VARCHAR will be always converted to INT and to NVARCHAR.
Use the below script to indentify queries with implicit conversion. [Source].
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name],
t.text AS [Query Text],
qs.total_worker_time AS [Total Worker Time],
qs.total_worker_time/qs.execution_count AS [Avg Worker Time],
qs.max_worker_time AS [Max Worker Time],
qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time],
qs.max_elapsed_time AS [Max Elapsed Time],
qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads],
qs.max_logical_reads AS [Max Logical Reads],
qs.execution_count AS [Execution Count],
qs.creation_time AS [Creation Time],
qp.query_plan AS [Query Plan]
FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK)
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp
WHERE CAST(query_plan AS NVARCHAR(MAX)) LIKE ('%CONVERT_IMPLICIT%')
AND t.[dbid] = DB_ID()
ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
4. Change compatibility level
After updating your SQL Server, make sure to update the compatibility level of your database to the highest level supported by the current version of your SQL Server.
You can change your SQL Server compatibility level using SQL Server Management Studio or with TSQL query. [Source].
ALTER DATABASE <YourDatabase>
SET COMPATIBILITY_LEVEL = { 150 | 140 | 130 | 120 | 110 | 100 | 90 }
5. Find and Create missing indexes
Create your missing indexes. But, don’t create them all. Create the first 10 missing indexes in your database. Stick to having around 5 indexes per table.
You can use the next script to find the missing indexes in your database. [Source]. But, don’t blindly add new indexes. Check the indexes you already have and the estimated impact of the missing indexes.
SELECT TOP 25
dm_mid.database_id AS DatabaseID,
dm_migs.avg_user_impact*(dm_migs.user_seeks+dm_migs.user_scans) Avg_Estimated_Impact,
dm_migs.last_user_seek AS Last_User_Seek,
OBJECT_NAME(dm_mid.OBJECT_ID,dm_mid.database_id) AS [TableName],
'CREATE INDEX [IX_' + OBJECT_NAME(dm_mid.OBJECT_ID,dm_mid.database_id) + '_'
+ REPLACE(REPLACE(REPLACE(ISNULL(dm_mid.equality_columns,''),', ','_'),'[',''),']','')
+ CASE
WHEN dm_mid.equality_columns IS NOT NULL
AND dm_mid.inequality_columns IS NOT NULL THEN '_'
ELSE ''
END
+ REPLACE(REPLACE(REPLACE(ISNULL(dm_mid.inequality_columns,''),', ','_'),'[',''),']','')
+ ']'
+ ' ON ' + dm_mid.statement
+ ' (' + ISNULL (dm_mid.equality_columns,'')
+ CASE WHEN dm_mid.equality_columns IS NOT NULL AND dm_mid.inequality_columns
IS NOT NULL THEN ',' ELSE
'' END
+ ISNULL (dm_mid.inequality_columns, '')
+ ')'
+ ISNULL (' INCLUDE (' + dm_mid.included_columns + ')', '') AS Create_Statement
FROM sys.dm_db_missing_index_groups dm_mig
INNER JOIN sys.dm_db_missing_index_group_stats dm_migs
ON dm_migs.group_handle = dm_mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details dm_mid
ON dm_mig.index_handle = dm_mid.index_handle
WHERE dm_mid.database_ID = DB_ID()
ORDER BY Avg_Estimated_Impact DESC
GO
6. Delete most of your indexes
Indexes reduce perfomance all the time. They reduce performance of inserts, updates, deletes and selects. Even if a query isn’t using an index, it reduces performance of the query.
Delete most your indexes. Identify your main table and check if it has more than 5 indexes. But, don’t create indexes on every key of a JOIN.
Also, keep in mind if you rebuild an index for a table, SQL Server will remove all plans cached related to that table.
Rebuilding your indexes is the most expensive way of updating statistics.
You can find your unused indexes with the next script. [Source]. Look for indexes with zero seeks/scans and lots of updates. They’re good candidates to drop.
SELECT TOP 25
o.name AS ObjectName
, i.name AS IndexName
, i.index_id AS IndexID
, dm_ius.user_seeks AS UserSeek
, dm_ius.user_scans AS UserScans
, dm_ius.user_lookups AS UserLookups
, dm_ius.user_updates AS UserUpdates
, p.TableRows
, 'DROP INDEX ' + QUOTENAME(i.name)
+ ' ON ' + QUOTENAME(s.name) + '.'
+ QUOTENAME(OBJECT_NAME(dm_ius.OBJECT_ID)) AS 'drop statement'
FROM sys.dm_db_index_usage_stats dm_ius
INNER JOIN sys.indexes i ON i.index_id = dm_ius.index_id
AND dm_ius.OBJECT_ID = i.OBJECT_ID
INNER JOIN sys.objects o ON dm_ius.OBJECT_ID = o.OBJECT_ID
INNER JOIN sys.schemas s ON o.schema_id = s.schema_id
INNER JOIN (SELECT SUM(p.rows) TableRows, p.index_id, p.OBJECT_ID
FROM sys.partitions p GROUP BY p.index_id, p.OBJECT_ID) p
ON p.index_id = dm_ius.index_id AND dm_ius.OBJECT_ID = p.OBJECT_ID
WHERE OBJECTPROPERTY(dm_ius.OBJECT_ID,'IsUserTable') = 1
AND dm_ius.database_id = DB_ID()
AND i.type_desc = 'nonclustered'
AND i.is_primary_key = 0
AND i.is_unique_constraint = 0
ORDER BY (dm_ius.user_seeks + dm_ius.user_scans + dm_ius.user_lookups) ASC
GO
Voilà! These are six tips I learned from Pinal Dave to start tuning your SQL Server. Pay attention to your implicit conversions. You can get a surprise.
I gained a lot of improvement only by fixing implicit conversions. In a store procedure, we had a NVARCHAR parameter to compare it with a VARCHAR column. Yes, implicit conversions happen between VARCHAR and NVARCHAR.
For more SQL content, check my posts on how to write dynamic SQL queries and the differences between TRUNCATE and DELETE.
Happy SQL time!